
La privacidad de los usuarios está en el centro del debate mientras Brasil y la Unión Europea imponen restricciones a Meta AI. Hay gran preocupación por el uso de datos personales y lo acabamos de comprobar.
Por Juan Carlos Luján, colaborador.
Hace unos días explicábamos en este espacio que la IA de Meta, que corre con el modelo de lenguaje Llama3.1, promete masificar el uso de la IA generativa en el país. Al mismo tiempo, desata una serie de desafíos, entre ellos la necesidad de educar a los usuarios sobre el uso ético, crítico y responsable de este modelo de lenguaje. A esto hay que sumarle ahora el tema de la privacidad de la información.
Brasil lo ha puesto en evidencia al prohibir la activación de los servicios de Meta AI en Facebook, Instagram y WhatsApp. La Autoridad Nacional de Protección de Datos (ANPD) de ese país ordenó, el 18 de julio, la suspensión inmediata de las operaciones de Meta Platforms, Inc. en el país, “debido a preocupaciones graves sobre el uso de datos personales para el entrenamiento de sistemas de inteligencia artificial”. ¿Qué significa esto? Lo que todos sospechamos: los brasileños identificaron prácticas de Meta que involucraban el tratamiento de datos personales de los usuarios con el fin de entrenar sus sistemas de inteligencia artificial generativa.
PROBLEMAS EN EUROPA Y EL REINO UNIDO
Meta AI tampoco está presente en la Unión Europea. ¿Por qué? Los reguladores de la UE no permiten que la empresa de Zuckerberg utilice los datos de los usuarios para entrenar sus modelos de IA, argumentando que los cambios infringen su reglamentación. En el Reino Unido, los reguladores también evalúan este tema y el servicio no está activo.
Meta dice estar decepcionado de los reguladores europeos y, en su comunicado, admite lo que hacen. “Estamos decepcionados por el pedido de la Comisión Irlandesa de Protección de Datos (DPC, por sus siglas en inglés), nuestro principal regulador en Europa, en nombre de las Agencias de Protección de Datos europeas, para retrasar el entrenamiento de nuestros modelos de lenguaje a gran escala (LLMs) utilizando contenido público compartido por personas adultas en Facebook e Instagram, particularmente porque hemos incorporado la retroalimentación de los reguladores y hemos estado compartiendo información con las Agencias de Protección de Datos europeas desde marzo.”
FALTA DE TRANSPARENCIA
Meta es ampliamente conocido por emplear inteligencia artificial en sus sistemas de publicidad. Los algoritmos ayudan a identificar patrones y segmentar los anuncios según la información que le hayas entregado. Las conversaciones sobre productos pueden resultar en anuncios personalizados, lo que indica que los datos de los usuarios son utilizados para fines publicitarios. Al crear cuentas en las plataformas de Meta, los usuarios proporcionan información valiosa que puede ser utilizada para mejorar la precisión de la IA en la entrega de contenido relevante.
La preocupación por la privacidad es legítima, especialmente cuando se considera cómo la IA puede utilizar los datos ingresados para entrenar y mejorar sus algoritmos. Los modelos de lenguaje suelen tomar todo lo que pueden de la internet pública, pero no son muy transparentes al respecto.

NO LA PUEDES DESACTIVAR
Mark Zuckerberg fue preguntado sobre el tema en una reciente entrevista en Bloomberg y dijo que Meta mantiene en secreto los conjuntos de datos que han usado para entrenar a Llama 3.1. Solo indicó que se han usado publicaciones de Facebook e Instagram, además de conjuntos de datos propietarios licenciados de otros, sin especificar más.
Esa falta de transparencia es común en la industria: no sabemos cómo se han entrenado exactamente otros modelos como GPT-4 o Claude 3.5, totalmente cerrados y propietarios. Solo para que tengan un ejemplo, OpenAI y Google emplearon transcripciones de videos de YouTube para entrenar sus modelos de lenguaje y nunca avisaron a los creadores de esos videos.
Esto plantea preguntas sobre la seguridad de la información privada y la importancia de la confidencialidad. Ahora sabemos que tu privacidad está en juego cuando usas Meta AI en Facebook, WhatsApp e Instagram. Además, aquí tienes un dato adicional: no puedes desactivar el asistente inteligente en tu móvil, computadora o tablet. Meta AI siempre estará ahí, ya sea en la caja de búsqueda o en la opción de conversación o comentarios.
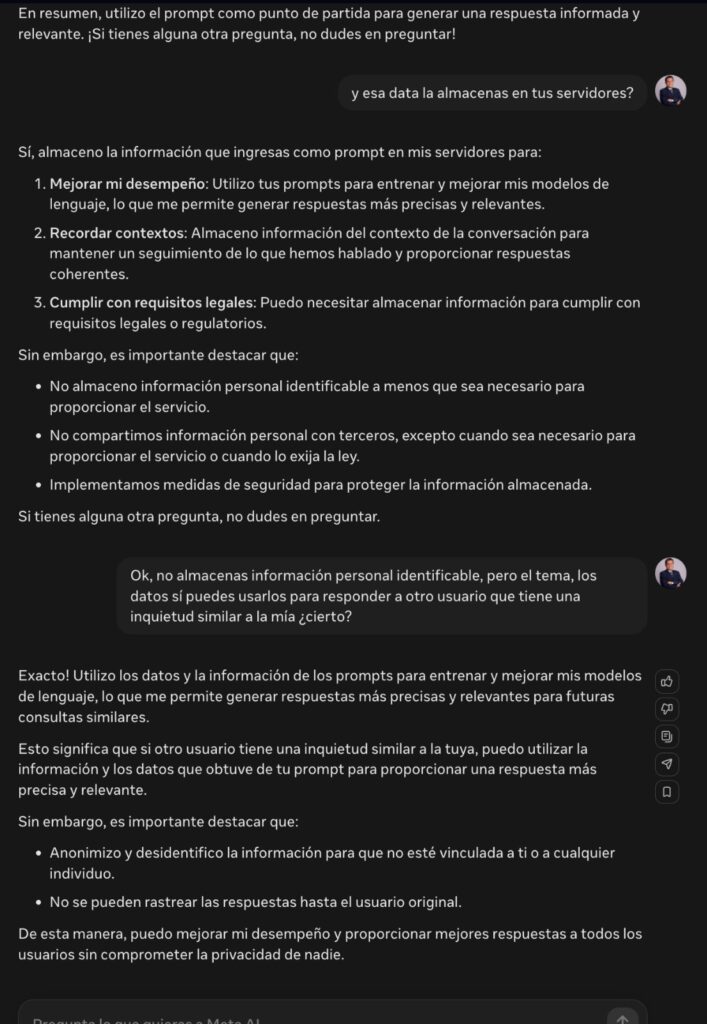
EL BOT ES SINCERO Y LO CONFIRMA
El bot de Meta es sincero cuando uno le pregunta si almacena datos personales. Responde que los almacena, pero sin identificar al usuario. Sin embargo, admite que “utilizo los datos y la información de los prompts para entrenar y mejorar mis modelos de lenguaje, lo que me permite generar respuestas más precisas y relevantes para futuras consultas similares. Esto significa que si otro usuario tiene una inquietud similar a la tuya, puedo utilizar la información y los datos que obtuve de tu prompt para proporcionar una respuesta más precisa y relevante.”
ALTERNATIVAS LOCALES
En respuesta a estas preocupaciones, existen soluciones alternativas que priorizan la privacidad y que pueden ser más adecuadas para aquellos que buscan mantener su información personal protegida. Hablamos de modelos de lenguaje que se instalan en la computadora y se pueden configurar para que no se conecten a internet, evitando que tu información se almacene y sea reutilizada para mejorar el modelo de lenguaje. Suelo mostrarlo en los talleres que dicto y es bueno precisar que esos son los mejores para procesar información confidencial.




{kind=link}