
Algunos alcances sobre Grok, desinformación y juicio crítico en las redes sociales
Por Juan Carlos Luján, columnista.
En las últimas horas se produjo una discusión intensa en X. Un grupo de usuarios, entre ellos varios periodistas experimentados, aseguró que las imágenes difundidas por la Agencia EFE sobre un bombardeo contra una escuela en Irán eran falsas y correspondían a Kabul en 2014. La acusación no era menor. Implicaba manipulación informativa en medio de una escalada militar.
Sin embargo, búsquedas inversas en Google mostraban que la fotografía circulaba en medios internacionales con fecha actual y crédito identificado. Posteriormente, la ONU confirmó que el ataque sí ocurrió y que hubo víctimas, incluidas niñas.
Este caso es pedagógico. No por la confrontación política, sino por la forma en que se intentó desacreditar una cobertura mediante una vieja estrategia de desinformación: atribuir antigüedad falsa a una imagen reciente. No es una técnica nueva. Se ha utilizado en Siria, Gaza, Ucrania y en conflictos de diversa naturaleza. También aparece en contextos electorales como el nuestro. El objetivo no siempre es demostrar una mentira. A veces basta con sembrar duda. Y en redes sociales, la duda viaja más rápido que la evidencia.
Grok no es una fuente
Lo que sí resulta preocupante es que muchos usuarios, incluidos profesionales en comunicación, recurrieran a Grok para “confirmar” la veracidad de la información dentro de la propia plataforma. Y esto sí que debe alertarnos. Grok no es una fuente. Es un modelo de lenguaje que, a diferencia de otros como ChatGPT, Claude o Gemini, está integrado a X y suele responder con base en lo que circula en tiempo real. Si una narrativa falsa gana espacio en la conversación, el modelo tenderá a reproducirla porque procesa frecuencia, no veracidad.
«Grok no es una fuente. Es un modelo de lenguaje que, a diferencia de otros como ChatGPT, Claude o Gemini, está integrado a X y suele responder con base en lo que circula en tiempo real».
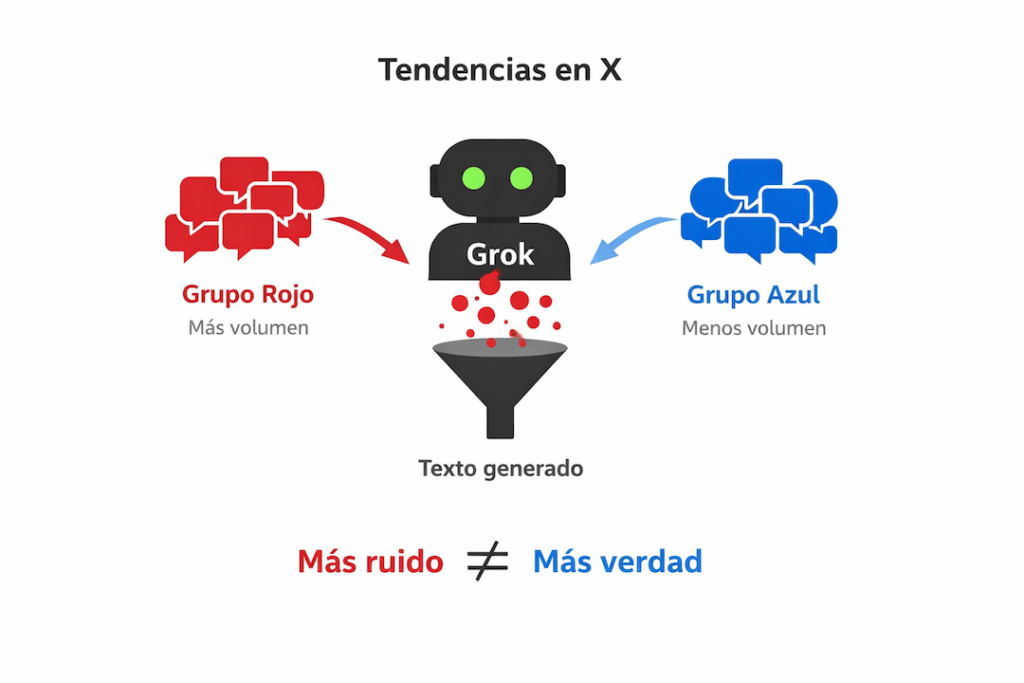
Cuando consultas a Grok, no está verificando hechos. No contrasta fuentes ni revisa evidencias. Genera texto en función de lo que más pesa en la conversación. Si en la conversación hay mayor volumen de mensajes que sostienen que la imagen es falsa, esa señal pesa en el cálculo probabilístico. El modelo prioriza patrones y frecuencia. No evidencia contrastada.
Un ejemplo lo explica mejor. Imaginemos dos grupos, uno rojo y uno azul. El rojo publica mucho más, genera mayor interacción y ocupa más espacio conversacional. El azul publica menos. Cuando el modelo procesa ese entorno, el rojo adquiere mayor presencia estadística. Eso no significa que el rojo tenga la verdad. Significa que tiene más volumen. Más ruido no equivale a mayor rigor.
En el caso concreto, la discusión digital intentó instalar la idea de manipulación. Sin embargo, la corroboración internacional desplazó el eje del debate. Informes preliminares señalaron que un ataque contra una escuela primaria de niñas en Minab, al sur de Irán, habría dejado más de cien víctimas, incluidas numerosas estudiantes. La protección de escuelas está contemplada en el derecho internacional humanitario. El Consejo de Seguridad de la ONU, mediante la Resolución 2601, recuerda la obligación de todas las partes de proteger centros educativos, estudiantes y personal docente.
Narrativa dominante
El contraste es evidente. Mientras en la red se debatía si la imagen era “de 2014”, los organismos multilaterales estaban verificando los hechos. Este desfase revela el problema de validar información dentro del mismo ecosistema donde se produce la controversia.
Un modelo probabilístico no distingue entre verdad factual y narrativa dominante. Distingue entre señales más frecuentes y menos frecuentes. Si una comunidad organizada amplifica una versión, esa versión puede adquirir mayor peso contextual. El sistema no tiene criterio editorial ni responsabilidad jurídica. Solo calcula probabilidades lingüísticas.
Esto no convierte a Grok en inútil. Puede servir para explorar debates o identificar narrativas en circulación. Pero usarlo como árbitro de veracidad dentro de la plataforma es metodológicamente débil. Es como preguntar en medio de una manifestación quién tiene razón y asumir que el grupo más ruidoso representa la verdad objetiva.
En entornos polarizados, la alfabetización digital exige un paso adicional. Verificar fuera de la plataforma. Consultar agencias de noticias, revisar comunicados oficiales, contrastar con organismos internacionales y, cuando sea posible, examinar metadatos y geolocalización. Esa es la diferencia entre reproducir conversación y ejercer verificación.
El episodio deja una lección más profunda. La inteligencia artificial no reemplaza el juicio humano. Amplifica el entorno donde opera. Si ese entorno está dominado por sospecha, polarización o campañas coordinadas, la respuesta generada reflejará esa atmósfera.
Por eso la advertencia es técnica, no ideológica. Grok no confirma hechos. Predice texto. Si el rojo produce más señales, el rojo pesa más en el cálculo. Eso no convierte su versión en cierta. Más presencia no es más verdad. Más volumen no es más evidencia. Y cuando hay vidas involucradas, confundir frecuencia con veracidad no es un error menor.




{kind=link}